Towards a computational model of social meta-inference and the evidentiary value of consensus
Abstract
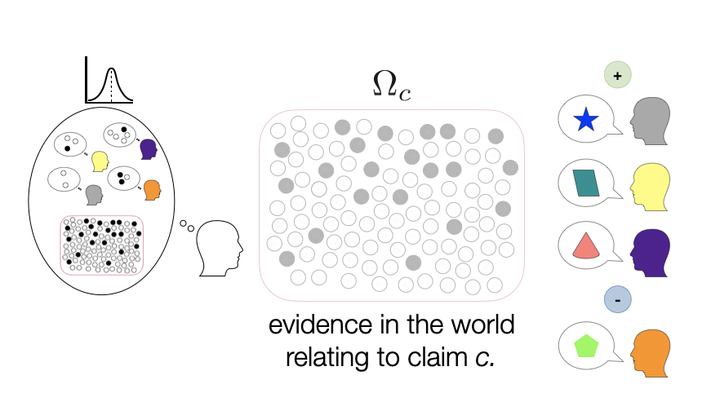
Reasoning beyond available data is a ubiquitous feature of human cognition. But while the availability of first-hand data typically diminishes with increasing complexity of reasoning topics, people’s ability to draw inferences seems not to. Reasoners may offset the sparsity of direct evidence with evidence that is inferred by observing the statements and actions of others. But this kind of social meta-inference comes with challenges of its own. In evaluating a claim about an unfamiliar topic, a reasoner might sensibly assume that a person who makes an argument in its favour is in possession of some evidence - but how much? How should the evaluation vary with the number of people arguing on each side? Should repeated arguments carry more weight than distinct ones? How people reason in this situation is likely to depend on their assumptions about the generative process behind communication. Here we present preliminary work towards a computational model of the kinds of inferences required when reasoning from indirect evidence, and we examine candidate model predictions via an experiment investigating the evidentiary strength of consensus in the context of social media posts. By systematically varying the degree of consensus along with the diversity of people and arguments involved we are able to assess the contribution of each factor to evidentiary weight. Across a range of topics where reasoning from first-hand data is more or less difficult we find that while people were influenced by the number of people on each side of an argument, the number of posts was the dominant factor in determining how people updated their beliefs. However, in contrast to well established premise diversity effects, our findings suggest that repeated arguments may carry more weight.